隐私计算实训营第二期-第七课
- 第七课:XGB算法与SGB算法开发实践
- 1 决策树模型
- 1.1 决策树的训练和预测过程
- 1.2 决策树的发展过程
- 2 GBDT模型
- 2.1 Boosting核心思想
- 2.2 GBDT原理
- 3 XGB模型
- 3.1 XGB核心思想
- 3.2 XGB优点
- 3 隐语纵向树模型
- 3.1 数据纵向分割
- 3.2 隐私保护的树模型算法
- 3.3 SS-XGB和SGB实现原理
- 3.4 开发流程
- 3.5 隐语实现上的优势
- 4 作业实战
- 4.1 使用SS-XGB进行训练
- 4.2 作业结果
第七课:XGB算法与SGB算法开发实践
首先必须感谢蚂蚁集团及隐语社区带来的隐私计算实训第二期的学习机会!
本节课由蚂蚁隐私计算部算法工程师邹沛成老师讲解。

本节课主要介绍隐语纵向树模型,据土豪包括数据纵向分割,XGB树模型,
以及以隐私计算的实现XGB模型的两种方式:秘密分享方式的SS-XGB,
联邦学习方式的SGB,内容目录如下:

在学习SS-XGB和SGB之前,我们应该了解基本的决策树模型、梯度提升决策树
GBDT模型以及XGBoost(eXtreme Gradient Boosting)模型。发现一个很好的
图解机器学习学习网站,下面这几个基本的模型都可以在这里学习到。我们借用
其中这几个模型讲解的图示,详细的学习链接请点击: 图解机器学习.
1 决策树模型
决策树(Decision tree)是基于已知各种情况(特征取值)的基础上,通过构建
树型决策结构来进行分析的一种方式,是常用的有监督的分类算法。决策树模型
模拟人类决策过程。以下面买衣服为例,一个顾客在商店买裤子,于是有了下面
的对话和决策:
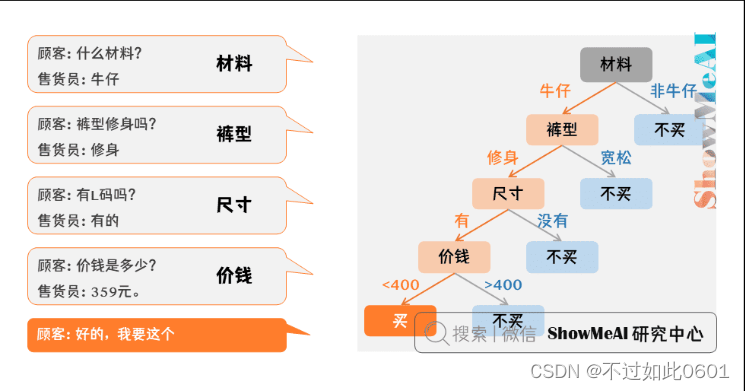
决策树模型核心是下面几部分:
- 结点和有向边组成。
- 结点有内部结点和叶结点俩种类型。
- 内部结点表示一个特征,叶结点表示一个类。
其中,每个内部结点表示一个属性的测试,每个分支表示一个测试输出,每个叶
结点代表一种类别。
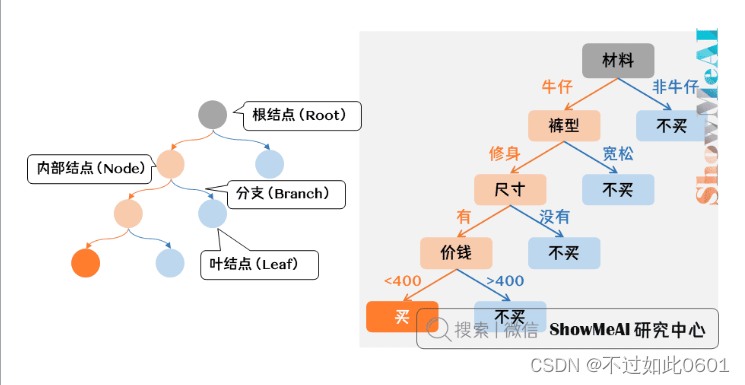
1.1 决策树的训练和预测过程
决策树的训练过程就是确定最优的划分属性,预测过程就是沿着划分属性依次判定,
直到到达叶节点的决策结果。
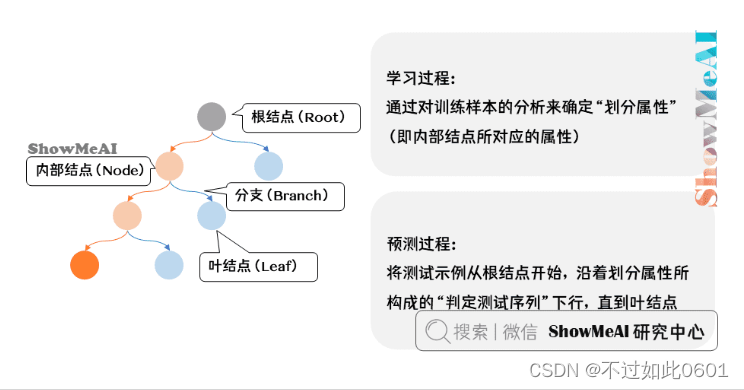
1.2 决策树的发展过程
决策树的训练过程就是确定最优的划分属性,预测过程就是沿着划分属性依次判定,
直到到达叶节点的决策结果。
决策树在发展过程中出现了很多的模型,这些模型主要是由在确定划分属性时不同
的信息增益函数定义带来的,典型的模型如ID3、C4.5、CART、RF、GBDT、XGB。

2 GBDT模型
实际中很少使用单棵的决策树,尤其是当属性特征比较多时,决策树的高度将变的
很高,拟合的难度也很大,因此产生了集成多棵弱决策树的集成思想。GBDT就是
这样的其中一种集成方式。
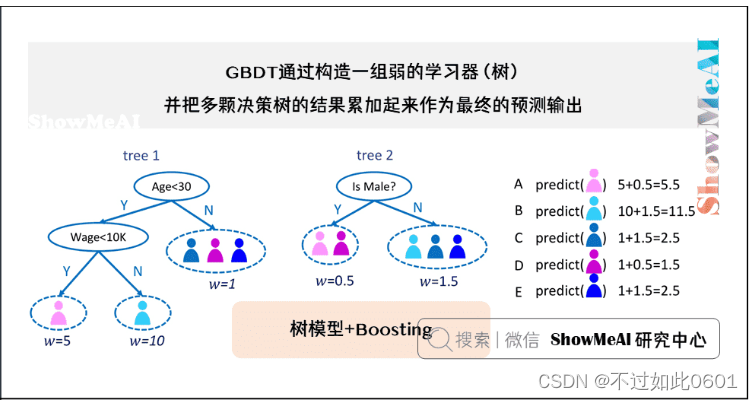
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代
的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一
组弱的学习器(单棵树),并把多棵决策树的结果累加起来作为最终的预测输出。
2.1 Boosting核心思想
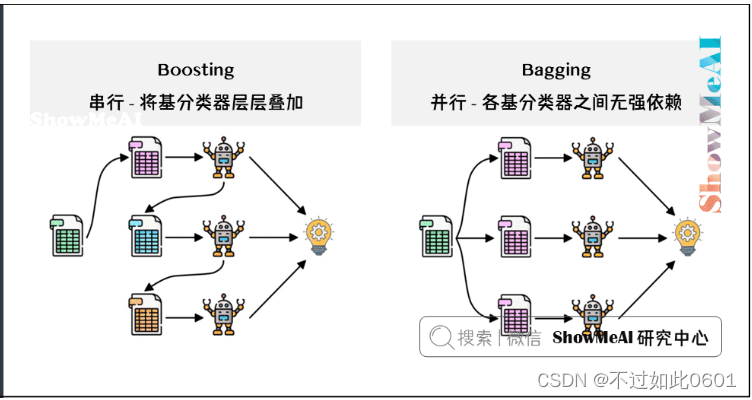
集成的方式主要有两种,一种是Boosting(串行,每次以前一个决策树为基础,代表
模型为GBDT,XGB),另一种是Bagging(Bootstrap aggregating的缩写, 并行,
将每个决策值累加起来,代表模型为随机森林RF)。
2.2 GBDT原理
GBDT的原理比较简单:
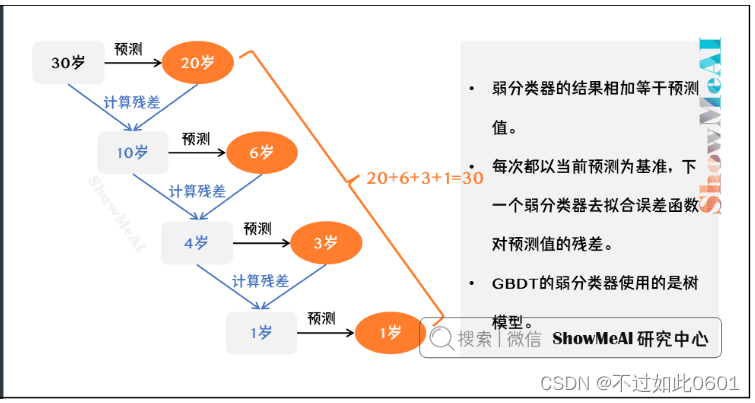
- 所有弱分类器的结果相加等于预测值。
- 每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差,
残差即为预测值与真实值之间的误差。 - GBDT的弱分类器使用的是树模型。
比如下面我们用 GBDT 去预测年龄:
第一个弱分类器(第一棵树)预测一个年龄(20岁),计算发现误差有6岁;
第二棵树预测拟合残差,预测值10,计算发现差距还有4岁;
第三棵树继续预测拟合残差,预测值3,发现差距只有1岁了;
第四课树用1岁拟合剩下的残差,完成预测。
最终,四棵树的结论加起来,得到30岁这个标注答案。
实际工程实现里,GBDT 是计算负梯度,用负梯度近似残差。
3 XGB模型
XGB是 eXtreme Gradient Boosting 的缩写称呼,它是一个非常强大的 Boosting
算法工具包,具有优秀的性能(并行计算效率、缺失值处理、控制过拟合、预测
泛化能力),现在很多机器学习方案依旧会首选这个模型。
3.1 XGB核心思想
前面说了Boosting的核心思想在于逐步累加决策值,对于训练的目标函数而言就是
逐步累加一个新的函数。

将上面的目标函数可以做如下变形,得到一个包含有二次项的目标函数:

训练的目的就是使目标函数最低,进一步使用泰勒展开来化简:

把常数项提出来(因为这是上一步的目标函数值),则当前步的目标函数可以
简化为:

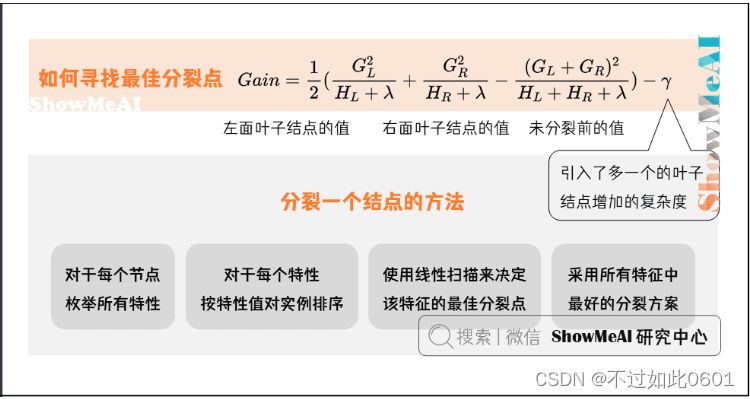
后面还需要重新定义树,并计算目标函数的最优值:

具体生成树的时候,使用贪婪算法来生成树:
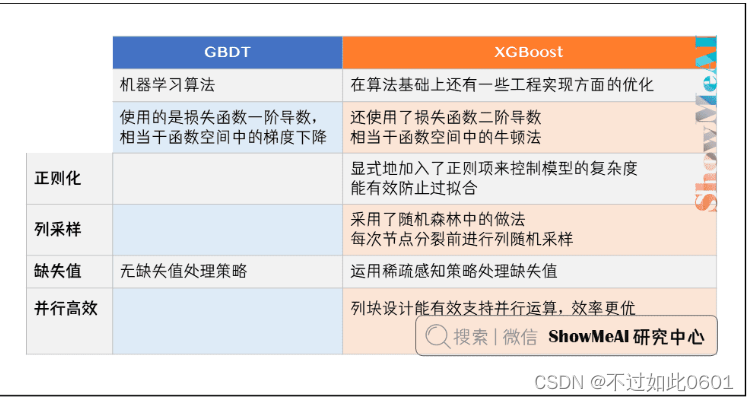
3.2 XGB优点
与GBDT模型比起来,XGB有如下的优点:
3 隐语纵向树模型
有了上面的基本认识,下面我们看隐语的纵向树模型

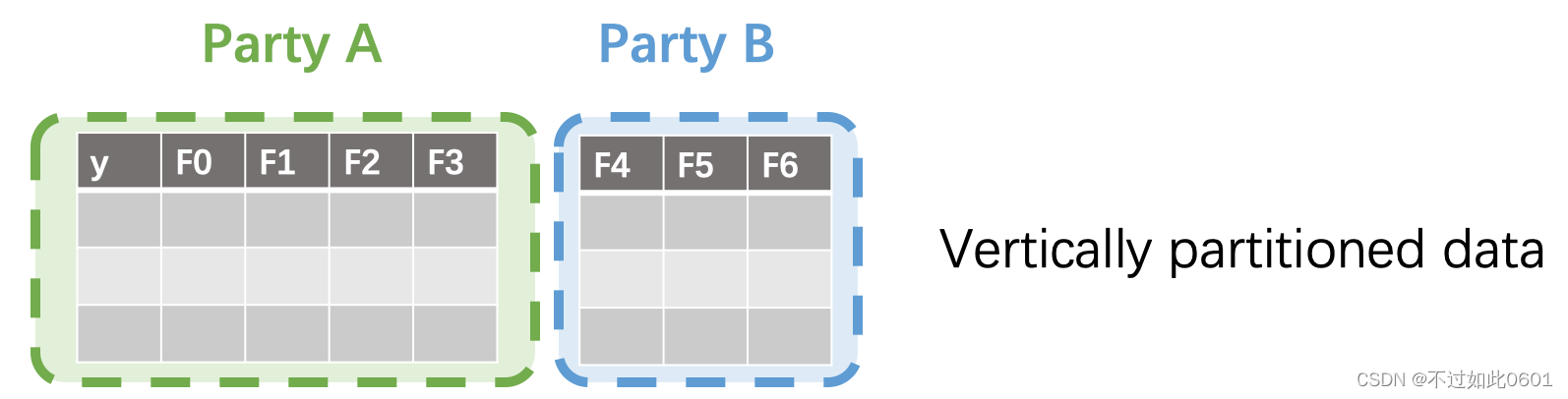
3.1 数据纵向分割
首先是垂直划分的数据集:
- 所有数据方的样本一致
- 但是拥有样本的不同特征
- 只有一方持有标签
3.2 隐私保护的树模型算法
隐语提供了两种隐私保护方法,基于秘密分享的SS-XGB和基于联邦学习的SGB。
其中SS-XGB安全性高,适用于网络带宽高,时延低的环境。SGB核心是使用同态
加密,适用于算力高的环境。

两种算法的详细区别如下:
首先是关注的密码协议不同:
一个是MPC协议,另一个是同态加密协议。

其次是参数不同:一个是仅含有XGB参数,另一个还需要设置联邦 学习的参数。

然后模型评估保存也不相同:一个是密态模型下的密态评估,各方持有分片。
一个是标签持有放单方面评估,预测结果为标签持有方是明文。

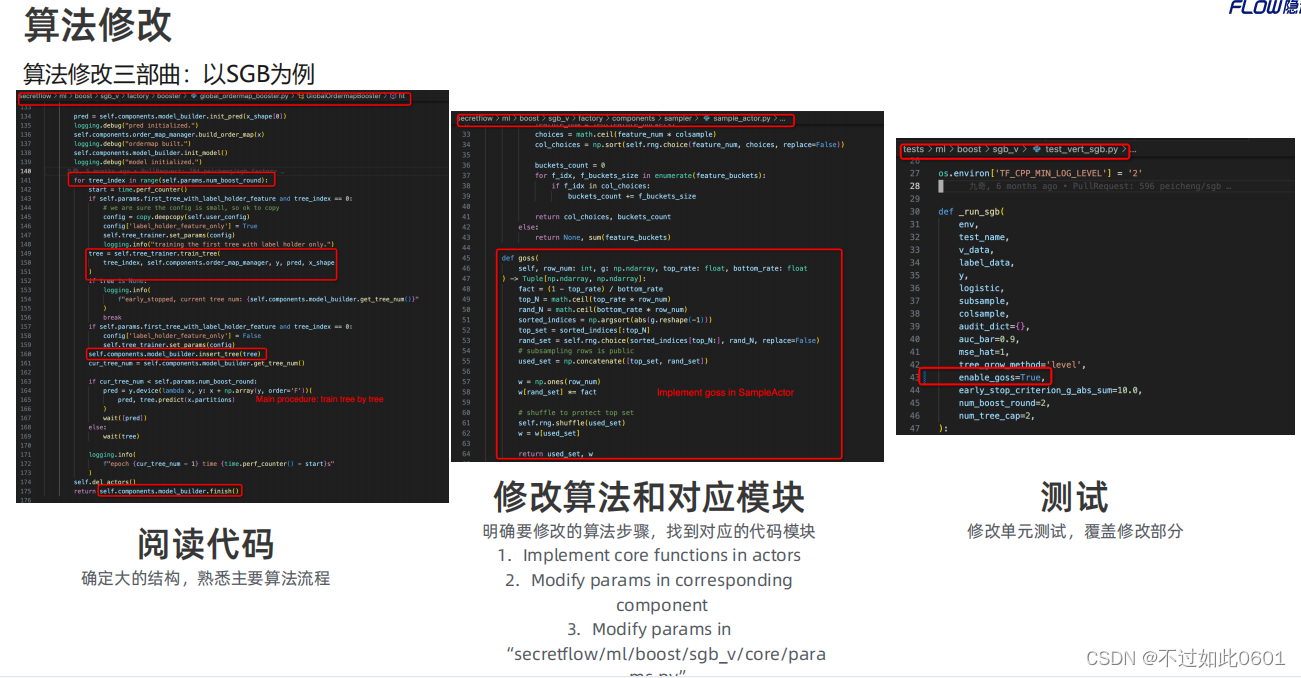
3.3 SS-XGB和SGB实现原理
主要分为三步对算法进行改造,算法原理参见: SS-XGB算法原理论文.

同样,SGB也有相应的算法改造过程:算法原理参见: SGB算法原理论文.

3.4 开发流程

3.5 隐语实现上的优势
隐语在实现上有如下的优势:

4 作业实战
本节课有如下的实践要求:

4.1 使用SS-XGB进行训练
1、建立网络
import secretflow as sf
import spu
import os
network_conf = {
"parties": {
"alice": {
"address": "alice:8100",
},
"bob": {
"address": "bob:8100",
},
},
}
party = os.getenv("SELF_PARTY", "alice")
sf.shutdown()
sf.init(
address="127.0.0.1:6379",
cluster_config={**network_conf, "self_party": party},
log_to_driver=True,
)
2、定义参数
alice, bob = sf.PYU("alice"), sf.PYU("bob")
spu_conf = {
"nodes": [
{
"party": "alice",
"address": "alice:8101",
"listen_addr": "alice:8101",
},
{
"party": "bob",
"address": "bob:8101",
"listen_addr": "bob:8101",
},
],
"runtime_config": {
"protocol": spu.spu_pb2.SEMI2K,
"field": spu.spu_pb2.FM128,
"sigmoid_mode": spu.spu_pb2.RuntimeConfig.SIGMOID_REAL,
},
}
#这里我们将使用spu的训练方式
3、读取数据
import pandas as pd
import os
from secretflow.data.vertical import read_csv as v_read_csv, VDataFrame
from secretflow.data.core import partition
current_dir = os.getcwd()
# load alice and bob data as a single vdataframe
data = v_read_csv(
{alice: f"{current_dir}/bank_0_8.csv", bob: f"{current_dir}/bank_8_16.csv"},
keys="id",
drop_keys="id",
)
# load alice's label data
alice_y_pyu_object = alice(lambda path: pd.read_csv(path, index_col = 0))(f"{current_dir}/bank_y.csv")
label = VDataFrame(partitions={alice: partition(alice_y_pyu_object)})
4、编码非数值的特征
# from data descryptions we know we need to encode data
from secretflow.preprocessing import LabelEncoder
encoder = LabelEncoder()
data['job'] = encoder.fit_transform(data['job'])
data['marital'] = encoder.fit_transform(data['marital'])
data['education'] = encoder.fit_transform(data['education'])
data['default'] = encoder.fit_transform(data['default'])
data['housing'] = encoder.fit_transform(data['housing'])
data['loan'] = encoder.fit_transform(data['loan'])
data['contact'] = encoder.fit_transform(data['contact'])
data['poutcome'] = encoder.fit_transform(data['poutcome'])
data['month'] = encoder.fit_transform(data['month'])
label = encoder.fit_transform(label)
5、分割数据
from secretflow.data.split import train_test_split as train_test_split_fed
X_train_fed, X_test_fed = train_test_split_fed(data, test_size=0.2, random_state=94)
y_train_fed, y_test_fed = train_test_split_fed(label, test_size=0.2, random_state=94)
6、进行训练
from secretflow.ml.boost.ss_xgb_v import Xgb
from secretflow.data.split import train_test_split as train_test_split_fed
import time
spu = sf.SPU(spu_conf) #这里我们更改为spu的训练方式
# init
ss_xgb = Xgb(spu)
start = time.time()
# 定义参数
params = {
'num_boost_round': 14,
'max_depth': 5,
'learning_rate': 0.3,
'sketch_eps': 0.1,
'objective': 'logistic',
'reg_lambda': 0.1,
'subsample': 1,
'colsample_by_tree': 1,
'base_score': 0.5,
}
# 训练模型
model = ss_xgb.train(params, X_train_fed, y_train_fed)
7、打印结果
from secretflow.device.driver import reveal
from sklearn.metrics import roc_auc_score
# we reveal and look at the evaluation score in cleartext, but there are safer alternatives
print(
"train set AUC score: ",
roc_auc_score(reveal(y_train_fed.partitions[alice].data), reveal(model.predict(X_train_fed))),
"test set AUC score: ",
roc_auc_score(reveal(y_test_fed.partitions[alice].data), reveal(model.predict(X_test_fed))),
)
4.2 作业结果
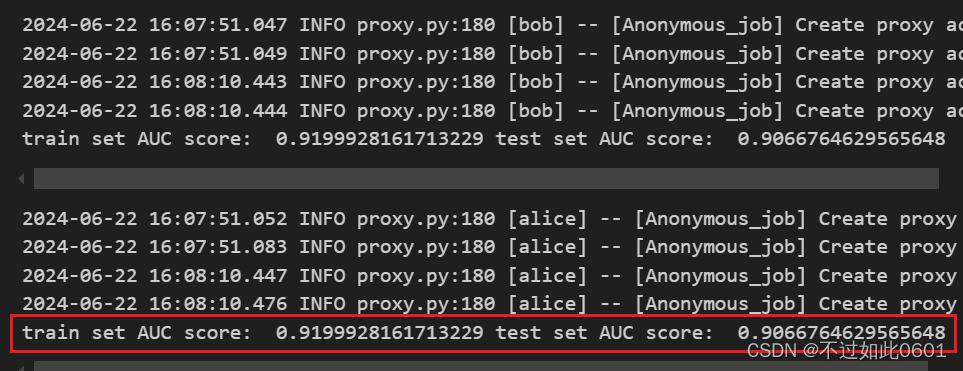
至此完成作业,输出结果为:
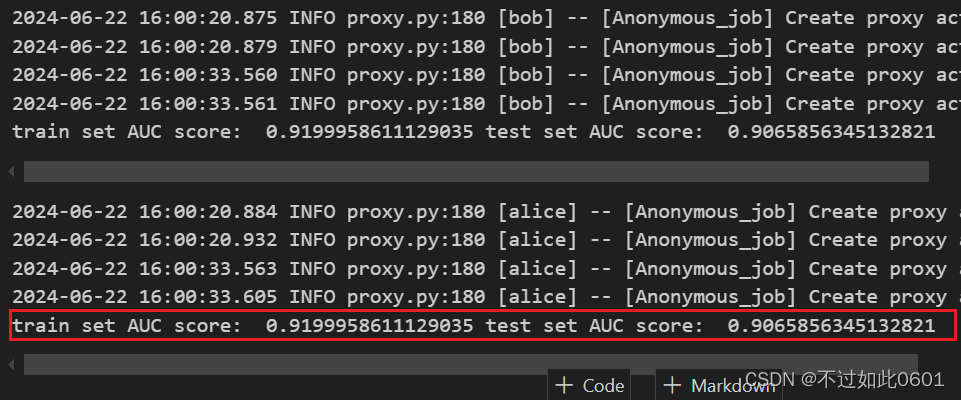
另外一个作业类似,需要先把数据集进行重新组合,一边有15个特征,另一边有1一个特征,训练代码改动不大,训练结果如下图。
分析:对比AUC值发现特征的分布不同并没有额外的AUC收益,这可以理解,因为训练效果的提高本质上是由于特征增加带来的,而不是特征在两边的分布数量差异。
至此,本节课程完毕。